This series is aimed at beginners in the SQL Server world or at those thrust into the role of DBA with little or no training. As such we’ll be focusing on some common concepts and doing so at a very high level. This series will not get especially technical nor will it cover topics in extreme detail. Also, the demo information will be done using mostly UI from SSMS and wizards as applicable rather than scripting. If being a full time SQL Server DBA is among your career goals you should consider this series of posts as only a starting point and seek further knowledge through other channels of learning.
In the first of what I hope will be a long series of posts aimed at the beginner or accidental DBA, we’ll cover the different types of files SQL Server utilizes.
The 2 default types of file are the data file, “ROWS Data” in the screenshot, and the transaction log file, “LOG”. These 2 files can be found on disk usually with the default file extensions “mdf” and “ldf” respectively. SQL Server will create new databases with exactly 1 data file and 1 log file by default.
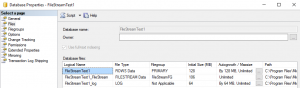 |
| The title of this article is “Why are there always 2 files?” yet the very first screenshot shows 3 distinct types of file. This was not an oversight, nor was it done to trifle with emotions, but rather to remind the reader that we are not covering this topic in full detail. If you want to learn more about the optional “FILESTREAM Data” option, click here to be taken to the appropriate MSDN article. |
Data files
The data file contains all of the data in all of the tables as well as all of the code in stored procedures, functions, views, etc. A database may have multiple data files. The new file(s) are generally named with a NDF extension to denote that they are secondary data files. When additional data files are added SQL Server will use all of them in a round robin.
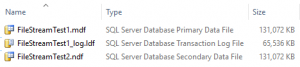
Why add more files? If there are more files then they can be spread across more logical volumes and increase IOPS available to the database. SQL Server also allows for specific database objects to be placed into specific files, although that will not be covered in this primer.
When a FULL backup is taken it is this file type that is backed up.
Log files
The transaction log file does not contain the data of your database, at least not directly. It is a list of transactions that have occurred against the database. Every time an action statement occurs against the database (insert, update, delete, create, alter, etc) those changes are written to the transaction log file. They are added and stored in the order in which they were received. The changes are NOT immediately written to the data file, a common misconception. The committed transactions listed in the log file are written to the data file in batch by a background process. That action is called a checkpoint.
If you’ve ever wondered how rollback statements work, this is your answer. To rollback a statement it simply needs to be canceled in the log, not “undone” to the data file.
When a transaction log backup is taken it is this file that is backed up.
While SQL Server allows for multiple log files it is generally advised not to utilize multiple log files outside of emergency situations.
One final note on log files. The transactions in the log file are not saved forever like the data in the data file. As such, the space in the log file is reused after a time. There will be much more detail about process that in a later post.
File growth
Upon creation of the database these files will be given a size as seen in the screenshot. The database likely isn’t using all of that space, but it is allocated from the OS all the same. As new data enters the database it uses that allocated, yet unused, space. Once the file on disk becomes full with data or transactions, it will need to increase in size to accommodate new transactions. SQL Server has options to manage that scenario. Clicking on the “Autogrowth / Maxsize” ellipses opens this window.
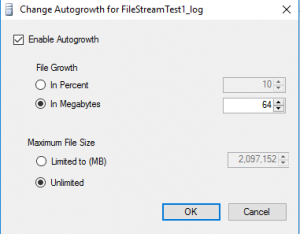
In this window we can tell SQL Server to grow that file as necessary without asking, an action called “Autogrowth”. This is the default behavior and is generally recommended. The file can be autogrown by a percent or number of megabytes. The default is percent, but megabytes is generally recommended. The file can also be limited with a maximum size. This setting is generally set to unlimited.
If a file becomes full and it is unable to grow to accommodate a request for any of these reasons the database will refuse all transactions until a remedy is brought about by a DBA. As a rule, this will happen at 2am on the busiest day of the year.
- Autogrowth is off
- The maximum file size has already been met
- Autogrowth is on and the maximum file size has not been met, but the logical volume on which it resides is full and cannot accommodate the larger file.
The error might look like this if your data file cannot grow.
Msg 1105, Level 17, State 2, Line 4
Could not allocate space for object ‘dbo.xyz’ in database ‘MyDatabase’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup.
Or like this if your log file cannot grow.
Msg 9002, Level 17, State 2, Line 5
The transaction log for database ‘MyDatabase’ is full due to ‘LOG_BACKUP’.
Thank you for reading. Next time we’ll be talking about what different recovery models mean and how they affect the transaction log file.
Great delivery. Sound arguments. Keep up the great work.
Wow, this article is good, my younger sister is analyzing these things, therefore I am going to tell her.