It is a pretty common need to find rows that exist in one dataset, but not in another. The question I will look to answer today is, “which way is best?”. For this test we are looking for rows that appear in a table called orderheader that aren’t also in a temporary table called #ords. The field that we are comparing is an INT called ord_hdrnumber and it is the Clustered Primary Key of each table.
We’ll compare the pros, cons, and performance of 4 popular methods to complete the task.
–NOT IN
SELECT a.ord_hdrnumber FROM orderheader a WHERE a.ord_hdrnumber NOT IN (SELECT b.ord_hdrnumber FROM #ords b);
GO
–LEFT JOIN
SELECT a.ord_hdrnumber FROM orderheader a LEFT OUTER JOIN #ords b ON a.ord_hdrnumber = b.ord_hdrnumber WHERE b.ord_hdrnumber IS NULL;
GO
–NOT EXISTS
SELECT a.ord_hdrnumber FROM orderheader a WHERE NOT EXISTS (SELECT 1 FROM #ords b WHERE b.ord_hdrnumber = a.ord_hdrnumber);
GO
–EXCEPT
SELECT a.ord_hdrnumber FROM orderheader a EXCEPT SELECT b.ord_hdrnumber FROM #ords b;
First, let’s look at some functionality differences. There are some pretty significant limitations to both the IN and the EXCEPT versions.
| How many columns can be selected in primary table? | How many columns can be used in the compare? | |
| NOT IN | Multiple | 1 |
| LEFT JOIN | Multiple | Multiple |
| NOT EXISTS | Multiple | Multiple |
| EXCEPT | Only those used in the comparison | Multiple |
The next step is to compare performance. I played with this in multiple environments that had 295, 430K, and 4.8M rows in the orderheader table. In each I played with various sizes of #ords ranging from 10 to 900,000 orders. In the results below we see no statistically significant difference between the different queries until we reach the large secondary data set. During those tests the NOT IN is a disaster and the other 3 remain largely interchangeable.
Primary Data Size (orderheader) / Secondary Data Size (#ords)
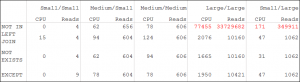
So where does that leave us? It would seem we can rule out NOT IN and EXCEPT for performance and functionality reasons. This leaves LEFT JOIN and NOT EXISTS. A closer look at the results shows that while small, there is a reduction in CPU usage on every sample when comparing just NOT EXISTS to LEFT JOIN.
Primary Data Size (orderheader) / Secondary Data Size (#ords)

The difference isn’t enough to make me never run a LEFT JOIN ever again, but I will lean towards the NOT EXISTS.